Monitoring on Yeti Root Zone Update
Background
Regarding the timing of Root Zone fetch and soa update, Each Yeti DM checks the root zone serial hourly to see if the IANA root zone has changed , on the following schedule:
| DM | Time |
|---|---|
| BII | hour + 00 |
| WIDE | hour + 20 |
| TISF | hour + 40 |
A new version of the Yeti root zone is generated if the IANA root zone has changed. In this model, root servers will pull the zone from one DM consistently for each new update, because 20 min is expected to be enough for root zone update for all root severs in ideal environment.
There is a finding in the past one Yeti root servers have long delay to update the root zone which is first reported in the Yeti experience I-D:
It is observed one server on Yeti testbed have some bugs on SOA update with more than 10 hours delay. It is running on Bundy 1.2.0 on FreeBSD 10.2-RELEASE. A workaround is to check DM’s SOA status in regular base. But it still need some work to find the bug in code path to improve the software.
To better understand the issue, we design a monitoring test and trace the behavior of zone update and DM selection of each Yeti root server. Now there is some preliminary result.
Methodology
To setup this monitoring, there are mainly three steps:
1.In the loop of DM, we ask each DM operator to use a special rname
2.In the loop of monitoring, it is simple to query soa record against each root server every minute. The information such as rname, the soa serial, and timestamp of the response is record.
3.Based on the data we collected, it is easy to figure out when the root zone update and where the zone is pulled, for each server and each soa serial.
Note that the time we observer a new zone update on a particular server includes the time of rtt and time error introduced by the interval(every minute) we measured. It is acceptable and does not impact the result and conclusions we made.
Preliminary result
There are there figures in the below to present the preliminary result for three continuous soa serial of Yeti. In the bar chart, the x-axis represent each root server with a bar. The value of bar in the y-axis is the delay in minute. We calculated the delay (di) of server i use the simple formula:
di=(Ti-Tmin)/60+10
- Ti is the timestamp for root server i to update the zone
- Tmin is the smallest timestamp of all server under a same soa serial
Note that we add 10 min to each value to make the bar chart more visible to figure out where the server pull the zone. So the actual delay is the value minus 10.
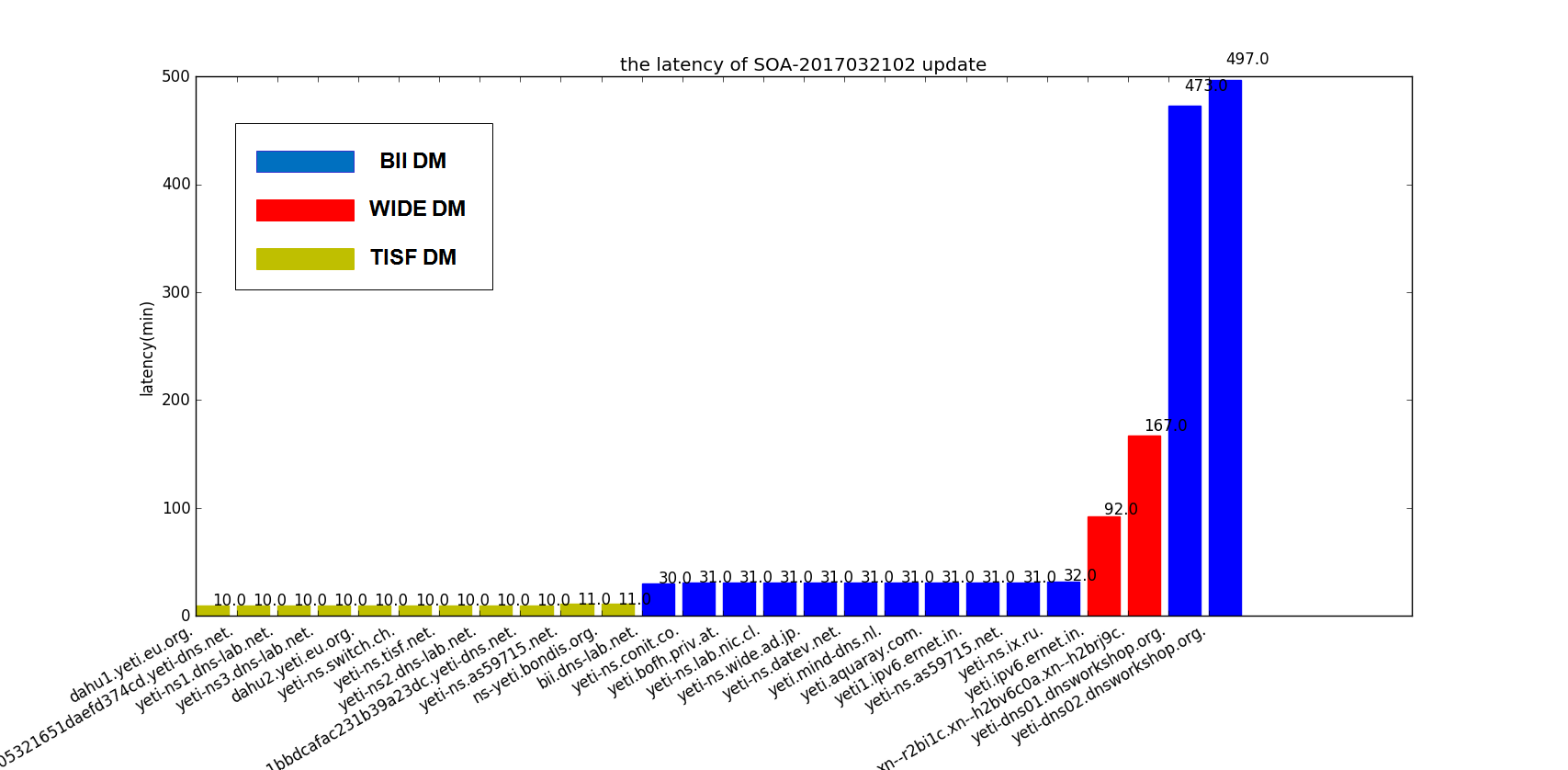
Figure 1 The latency of SOA 2017032102
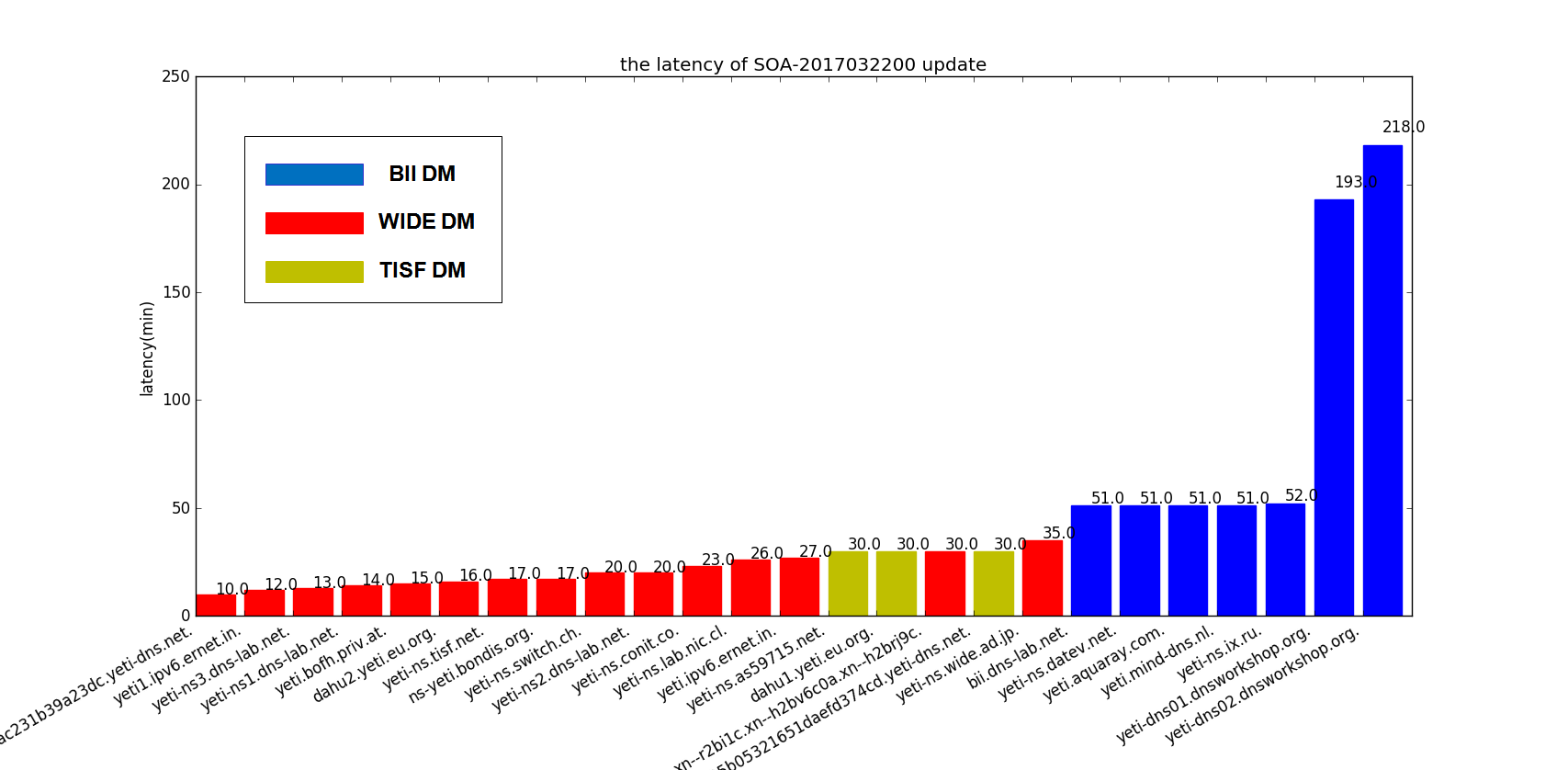
Figure 2 The latency of SOA 2017032200

Figure 3 The latency of SOA 2017032201
Intuitively there are some findings from the results:
- Two servers from dnsworkshop.org still endure high latency of zone update, as we reported before. This issue is not resolved.
- Besides the dnsworkshop.org servers, half of Yeti servers has more than 20 min delay, some even with 40 min delay. One possible reason may be that the server failed to pull the Zone on one DM and turn to another DM which introduces the delay.
- In figure 2, it is observed that server dahu2.yeti.eu.org. has two bars in the chart which means for the soa serial 2017032200 dahu2.yeti.eu.org. pull twice first from TISF DM secondly BII DM. It’s weird.
- Also in figure 2, it is observed that even in the same 20-minutes time frame, not all servers pull from a single DM. I guess may be some servers not use FCFS strategy to pull the zone after they receive the notify. They may pull the zone based on other metrics like the rtt , or manual preference.
Another findings: Double SOA RR
During the test, we happened to find that dahu2.yeti.eu.org has two soa record due to the multiple-DM settings in Yeti testbed. (We once reported the IXFR fallback issue due to Multiple-DM model.)
$dig @dahu2.yeti.eu.org . soa +short
www.yeti-dns.org. tisf.yeti-dns.org. 2017032002 1800 900 604800 86400
www.yeti-dns.org. wide.yeti-dns.org. 2017032001 1800 900 604800 86400
As far as I know, dahu2.yeti.eu.org uses Knot 2.1.0 at that time. We will check if everything goes well after it update to latest version.